
.png)
.png)
.png)
.png)
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius enim in eros elementum tristique. Duis cursus, mi quis viverra ornare, eros dolor interdum nulla, ut commodo diam libero vitae erat. Aenean faucibus nibh et justo cursus id rutrum lorem imperdiet. Nunc ut sem vitae risus tristique posuere.
Maecenas neque ultrices commodo lacinia molestie velenim etiam tempor enim eget turpis diam montes non etiam nunc elementum ac morbi fusce libero in odio amet.
Maecenas neque ultrices commodo lacinia molestie velenim etiam tempor enim eget turpis diam montes non etiam nunc elementum ac morbi fusce libero in odio amet.
Maecenas neque ultrices commodo lacinia molestie velenim etiam tempor enim eget turpis diam montes non etiam nunc elementum ac morbi fusce libero in odio amet.
Maecenas neque ultrices commodo lacinia molestie velenim etiam tempor enim eget turpis diam montes non etiam nunc elementum ac morbi fusce libero in odio amet.
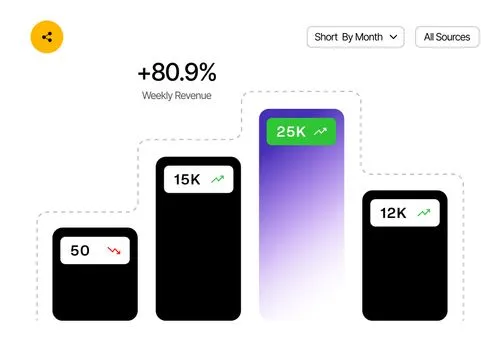


Lorem ipsum dolor sit amet, adipiscing elit. Donec sit amet nisi luctus, cursus tincidunt est cras fringilla leo orci fusce

Lorem ipsum dolor sit amet, adipiscing elit. Donec sit amet nisi luctus, cursus tincidunt est cras fringilla leo orci fusce

Lorem ipsum dolor sit amet, adipiscing elit. Donec sit amet nisi luctus, cursus tincidunt est cras fringilla leo orci fusce
Lorem ipsum dolor amet consectetur amet ullamcorper atsit eros risus.
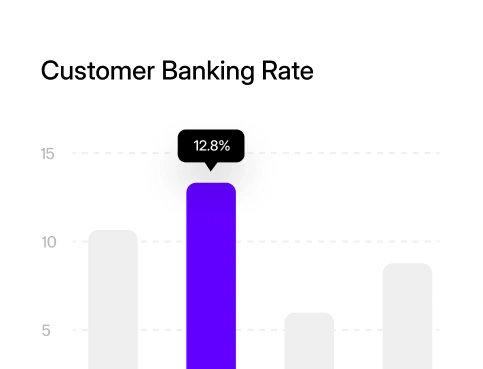
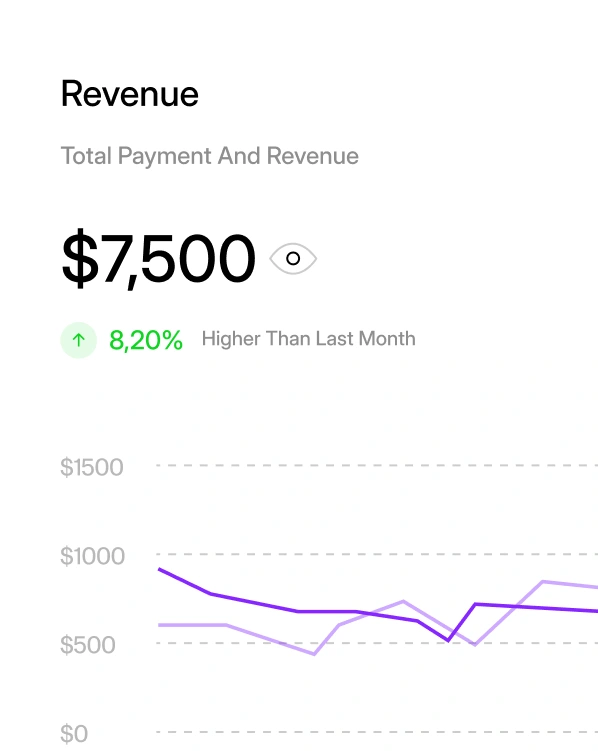
Lorem ipsum dolor amet consectetur amet ullamcorper atsit eros risus.





LIVA is a real-time avatar engine that makes AI conversations feel face-to-face. Avatars render on the client (any device or browser), so you don’t need cloud GPUs.
Chatbots type. LIVA talks, gestures, and reacts. You get lifelike lip-sync, expressions, and non-verbal cues—so the conversation feels human, not scripted.
A patent-pending interactive-streaming protocol renders video locally on users’ devices. That cuts infrastructure costs dramatically and keeps latency ultra-low.
Bring your own: OpenAI, Google Gemini, Anthropic, Mistral, Cohere, local endpoints—mix and switch as you like. LIVA is model-agnostic.
Yes. LIVA runs in modern web browsers and inside mobile apps via WebViews today. A React Native SDK is planned, with native iOS/Android SDKs to follow on the roadmap.
Sub-second end-to-end in typical conditions (network dependent). The goal is to keep it “blink-fast” so turn-taking feels natural.
No. Rendering happens client-side. Your only server costs are your LLM/TTS usage and routine API calls.
Yes. Add PDFs, docs, FAQs, or URLs. LIVA indexes your content so avatars answer with brand-accurate information. Update it anytime.
Completely. Theme outfits, backgrounds, camera framing, gestures, tone, and safety level. Save presets per product or market.
Avatar & voice cloning is coming soon. You’ll be able to turn a single photo and short audio sample into your digital twin. (Early access waitlist available.)
LIVA supports multiple major languages and a range of TTS providers (e.g., ElevenLabs). Pick voices per locale; swap providers as needed.
Rendering is local to the device. You choose where model calls go (your preferred LLM provider). Conversation storage is opt-in. Enterprise controls (logging, redaction, data retention) are available.
Avatars render locally, but most real-time experiences need a network connection for LLM/TTS. You can cache scripts for limited offline flows.
Because rendering happens on users’ devices, LIVA scales horizontally with your audience. Serve thousands of simultaneous conversations without GPU farms.
Add a few lines of JS to embed an avatar widget, point it at your model endpoint, and (optionally) connect your knowledge base. Sample projects and a quick-start guide are provided.
For developers, pricing is usage-based (per-token/voice minutes). Businesses can license custom avatars and enterprise features. The consumer app offers a free tier with an optional premium subscription. (See the pricing page for current details.)
Yes, with the right guardrails. You can enforce content policies, routing, redaction, and human-handoff. For regulated deployments, talk to us about compliance needs.
Yes. For example, LIVA powers a smart concierge in Dubai taxis, helping riders get instant guidance during trips.
Docs, sample code, and community channels are available for builders. Enterprise customers get priority support and SLAs.
